延迟物化 Late Materialization
延迟物化 Late Materialization
思考几个问题
- 数据库性能优化都有哪些方式?
- 合理的索引?
- 分表?
- 读写分离?
- JOIN代替子查询?
- ???
- 2000亿数据的表A和500万数据的表B进行Join查询, 再根据某个字段的分组聚合得到查询结果。OLTP/OLAP数据库是如何在这个数据体量下获得高性能查询的?
存储模型
在数据库存储上,通常有两类存储模型:
- 行式存储NSM(N-ary Storage Model)
- 列式存储DSM(Decomposition Storage Model)
有的数据库会结合上述模型,出现第三种方式: 行列混存。
NSM
一般是将一行数据完整的从头到尾连续存储(超长的字段一般会单独存储,行内记录逻辑地址),连续多行构成一个页,页的尾部通常会存储索引来解决record不定长时的快速查找问题。
以行为单位存储,再配合以 B+ 树或 SS-Table 作为索引,就能快速通过主键找到相应的行数据。
insert/update/delete/point lookup query(点查)的场景是占优的, 因此大多用于TP数据库。
缺点:
在读取时,会读取大量无效列数据,每次读取 record,都可能会引起 cache miss。对 cpu cache 非常不友好。
文件格式代表:
Avro、JSON、CSV、Raw Text file、Binary
产品(只在存储模型上的粗略区分):
Oracle(12c+)、DB2、MySQL、SQL SERVER、... ...
DSM
在存储时将多行数据的相同column连续存储在一起,相同column的数据组成一个一个的块(Block)。
非常适用于大量复杂查询的场景。
缺点:
列更新性能差!
- 每insert/update/delete 一行数据,需要同时修改多个列(会去更新存在不同位置的 column),带来IO放大,且为随机IO。
文件格式代表:
Parquet、ORC
产品(只在存储模型上的粗略区分):
Hbase、Vertica、GBase、... ...
行列混存
产品(只在存储模型上的粗略区分):
Doris、OpenGauss、GaussDB(DWS)、StarRocks、AnalyticDB MySQL、PolarDB-X、PolarDB MySQL、... ...
实际存储差异
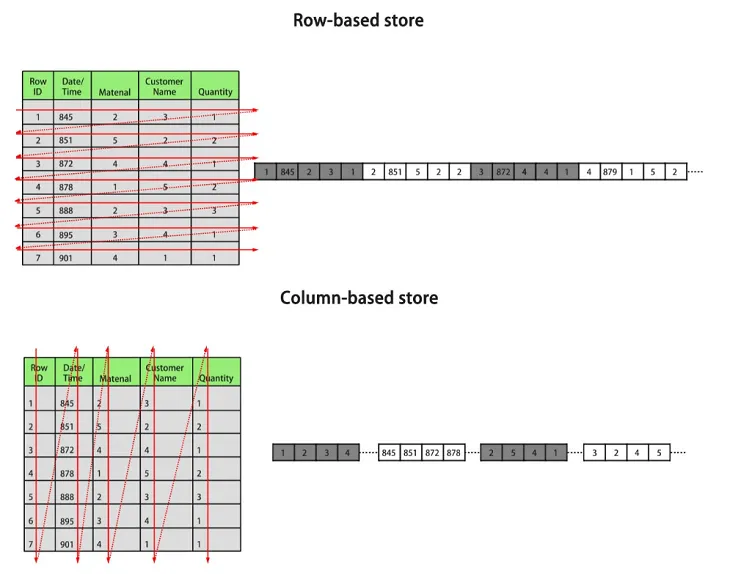
行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。
openGauss 中的行存与列存
默认情况下,openGauss 创建的表为行存储引擎。如果需要建立列存储引擎的表,需要在建表语句中指定属性 ORIENTATION = COLUMN。
客户价值 PK 性能
在大宽表、数据量比较大的场景中,查询经常关注某些列,行存储引擎查询性能比较差。
例如,气象局的场景,单表有200~800个列,查询经常访问10个列,在类似这样的场景下,向量化执行技术和列存储引擎的特性可以极大的提升性能和减少存储空间。
Why?
选择存储引擎的最佳实践
更新频繁程度
- 数据如果频繁更新,选择行存。
插入频繁程度
- 频繁的少量插入,选择行存。一次插入大批量数据,选择列存。
表的列数
- 表的列数很多,但更新不频繁,选择列存。
查询的列数
- 如果每次查询时,只涉及了表的少数(小于总列数的50%)字段,选择列存。
压缩率
- 列存表比行存表压缩率高。但高压缩率会消耗更多的CPU资源。
Late Materialization
什么是物化?
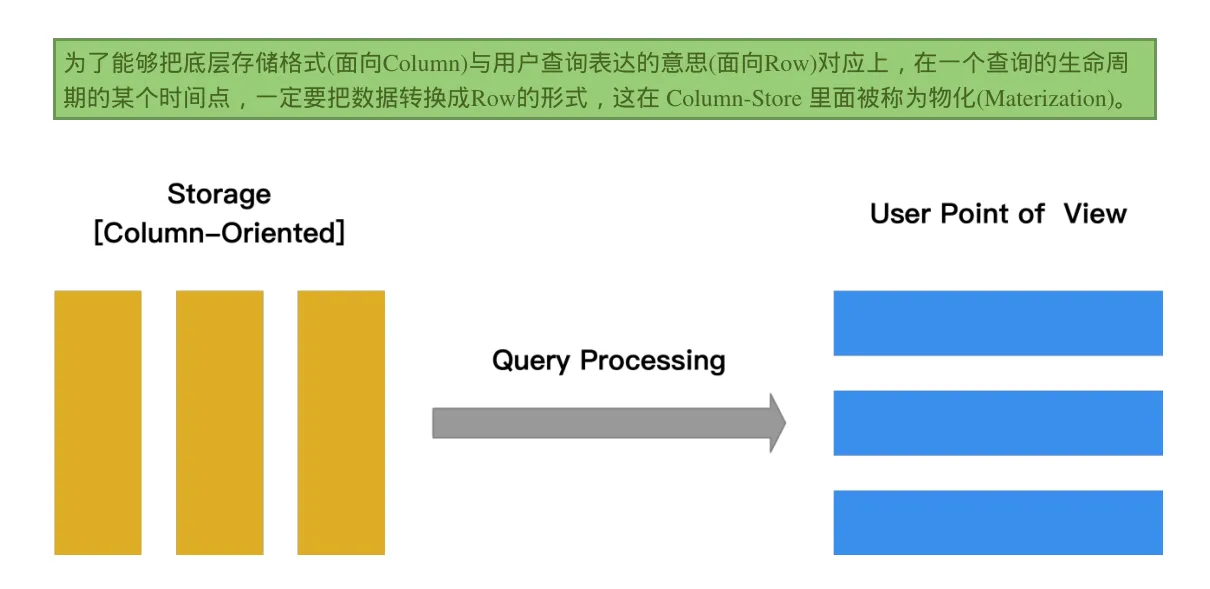
什么是延迟物化?
把这个物化的时机尽量的拖延到整个查询生命周期的后期。
把从各个列中获取的数据重新组装为行的过程称之为 tuple construction,late materialization 的目的就是尽可能推迟 tuple construction 的时机。
延迟物化意味着在查询执行的前一段时间内,查询执行的模型不是关系代数,而是基于 Column 的。
延迟物化原理
假设场景,执行 SQL
select name from person where id > 10 and age > 20
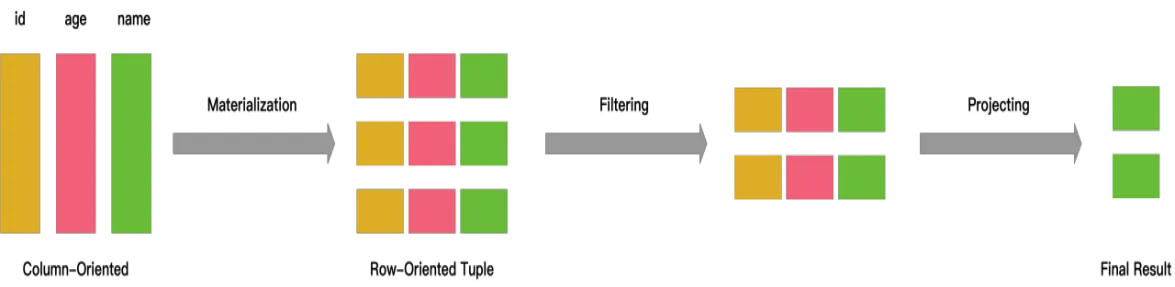
行存是如何实现的
从文件中读出三列的所有数据,物化成行数据:一行行的 person 数据。
然后应用两个过滤条件:id > 10 and age > 20,Filter之后从数据里面抽出 name 字段,作为最后的结果进行output。
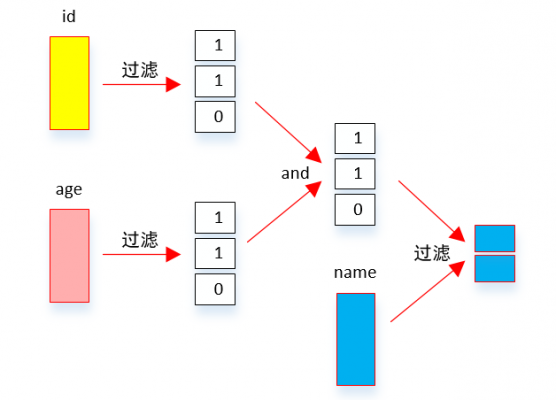
列存上,延迟物化的做法
- 直接在每一个Column 数据上分别应用过滤条件,从而得到两个满足过滤条件的 bitmap。
- 然后再把两个 bitmap 做位与操作得到同时满足两个条件的所有的 bitmap。
- 因为最后需要的是 name 字段,因此拿着这些 position 对 name 字段的数据进行过滤就得到了最终的结果
Late materialization 带来的好处
- 如果对物化进行延迟的话,可以减少物化的开销(因为要物化的字段少了),甚至直接不需要物化;
- 如果数据是被压缩过的,物化的过程就必须对数据进行解压,这会影响压缩带来的好处;
- 列式的内存组织形式对 CPU Cache 非常友好,从而提高计算效率,相反行式的内存组织形式因为非必要的列占用了 Cache Line 的空间,Cache 效率低;
- 块遍历的优化手段对 Column 类型的数据效果更好,因为数据以 Column 形式保存在一起,数据是定长的可能性更大。而如果 Row 形式保存在一起数据是定长的可能性非常小(因为你一行数据里面只要有一个是非定长的,比如 VARCHAR,那么整行数据都是非定长的)。
缺点
延迟物化且多表 Join 连接后, 许多 Join Algorithms 会对左(外)侧输入位置关系排序,右(内)侧输出位置不会排序(准确的说至少有一侧不会被排序),因为以这种无序的方式从列中提取值需要为每个位置跳转存储, 产生了随机访问,相比顺序访问会产生较大的开销。
对左(外)侧输入位置关系排序也有例外:对两组输入进行排序或重新分区的 Join 算法,不会对左右位置列表进行排序。
但无论哪种方式,至少有一组输出位置不会被排序。
延迟物化的特性实现给数据库带来了什么收益?
- 减少物化的tuple数量
- 降低IO、网络、计算压力
- 可以在列存(压缩)数据上进行高效计算
- 减少内存访问带来的开销
- 在扫描数据相对较少的情况下,需要cache的数据量更少,此时也会提高整个计算的cache命中率,减少cpu的消耗
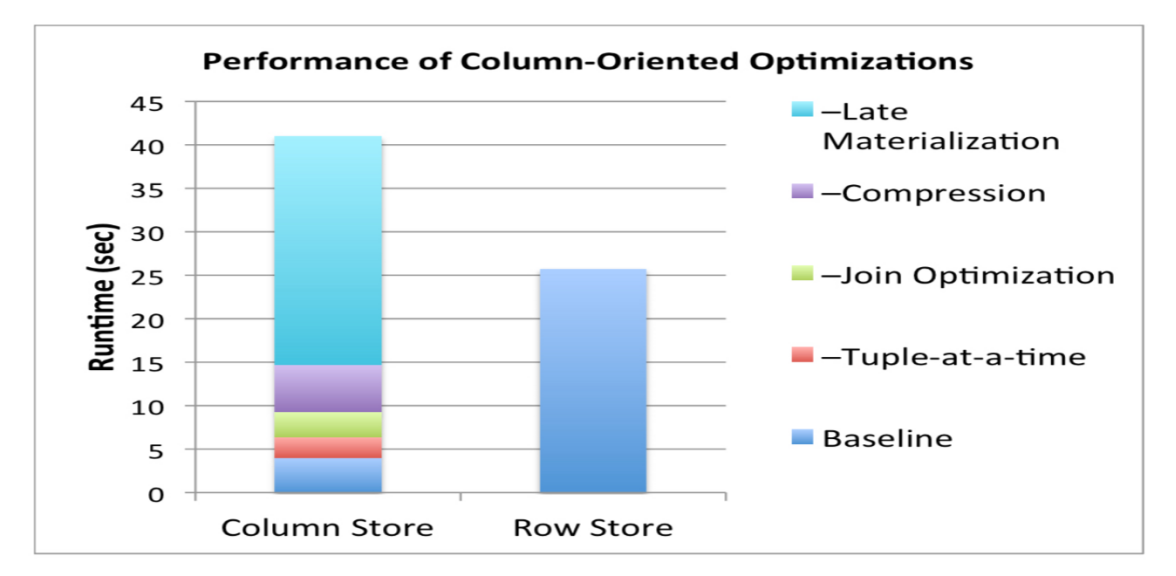
Join 查询
对于常见的多表查询,在数据库的内部实现分为很多: Hash-join、Invisible Join(隐式连接)、BroadcastJoin、LookupJoin、Jive-Join(使用两次排序解决 Unordered positional lookups)、SortJoin等等,不穷举。
延迟物化对Join的加速
对于 Join 而言,运算的核心在于两表中 Joinkey 的匹配上。对于其他列数据匹配上了就copy,匹配不上就丢弃。结合延迟物化,匹配后再加载其他列数据,可以极大的减少不必要的IO。
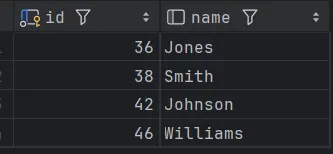
为了让查询结果更直观,此处的模拟数据让age字段的值与 dept_id的值相同。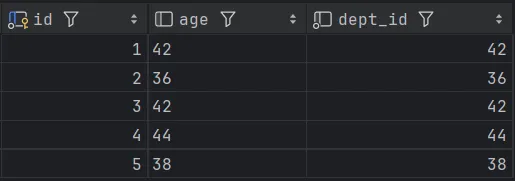
进行如下SQL查询:SELECT emp.age, dept.name FROM emp, dept WHERE emp.dept_id = dept.id
上述原始数据值可以以如下图的形式呈现: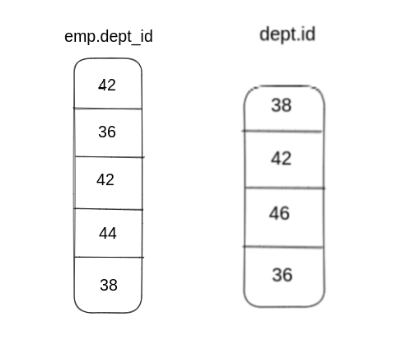
数据的查询过程中,我们先抽出 emp 表的 dept_id 和 dept 表的 id 列数据,进行匹配;并输出匹配结果对应原表的位置信息。
如下图所示,显示了 大小为 5 的列 与 大小为 4 的列 的Join结果, id存在交集的值为 [42, 36, 38]: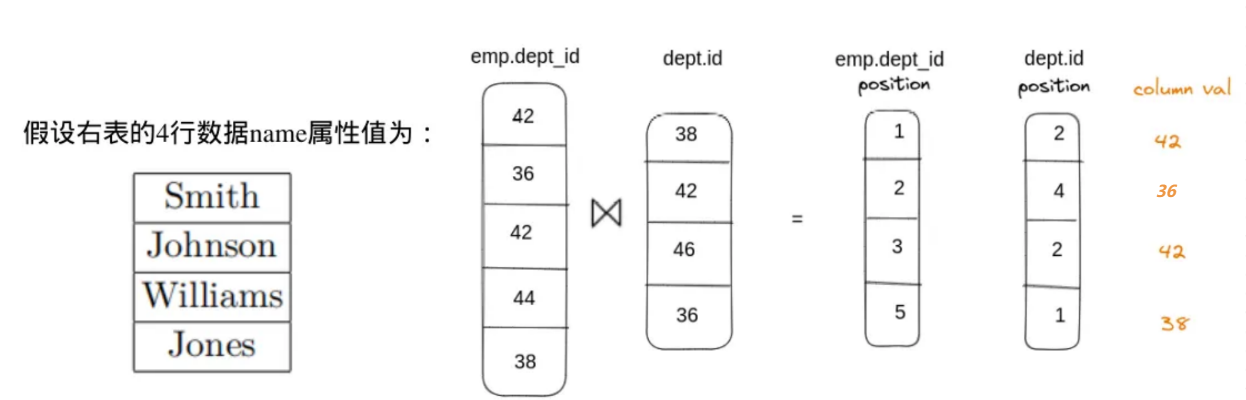
黄色文字部分是指position指向的值, 在实际Join中不会出现, 然后根据输出的位置信息,就可以从原始数据中抽取 age、name 列的数据得到 Join 最后的结果。
当然该算法能够产生明显优化效果的前提是 Join 的结果相较于原始数据比较小,这样才能够有效避免加载过多数据。
另外由于上图输出结果的第二列是无序的,如果回表查必然造成大量随机 IO,为了解决这个问题,Jive Join[参考文献 Fast Joins Using Join Indices]采用了对其进行排序之后再查询,即将随机 IO 转化为顺序 IO 的方法进行优化。
基于 Jive-Join 思想,在右侧表position列上添加一个额外的列(一个密集递增的整数序列):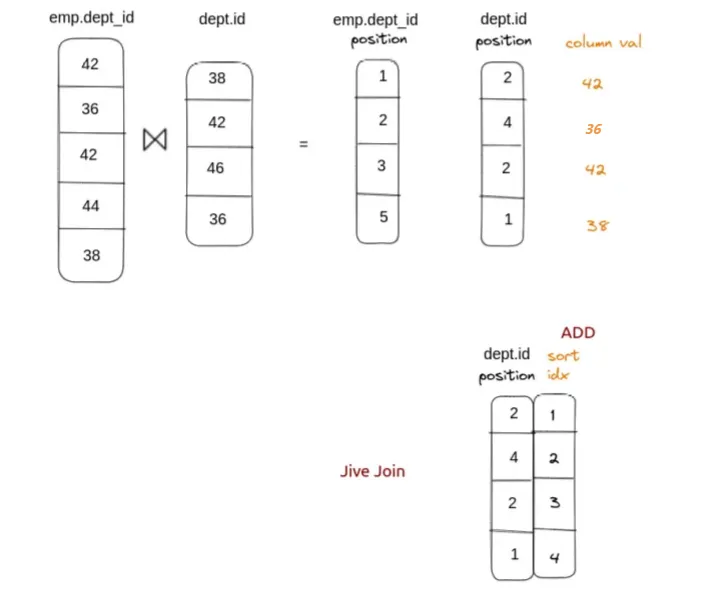
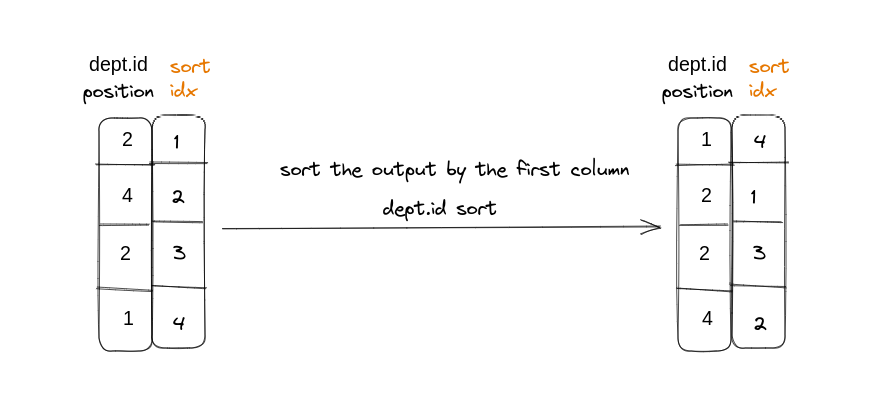
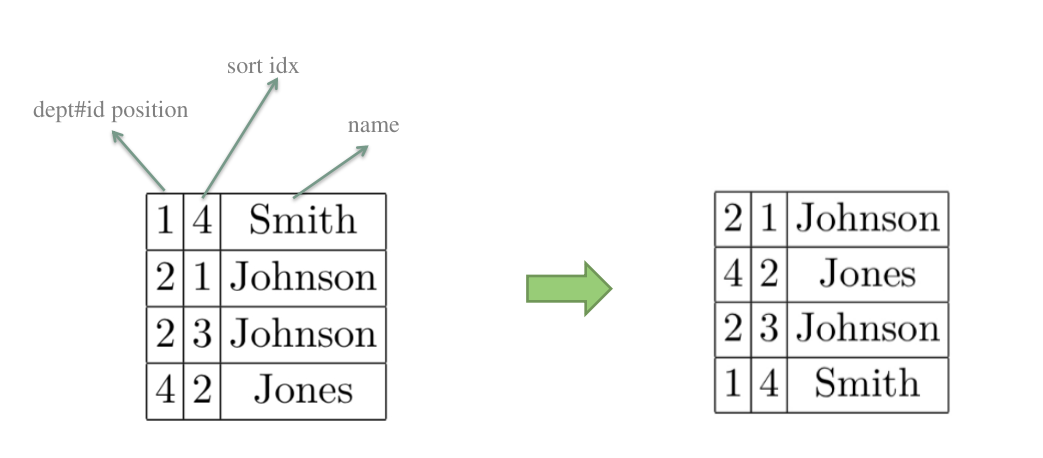
总结
- 物化: 将列数据转换为可以被计算或者输出的行数据或者内存数据结果的过程。
- 物化后的数据通常可以用来做数据过滤,聚合计算,Join。
- 延迟物化:尽可能推迟物化操作的发生。
- 缓存友好
- 节省CPU / 内存带宽
- 可以利用到执行计划和算子的优化,例如filter
- 可以直接在压缩列做计算