Unicode编码
Unicode编码
计算机发展早期,编码只有ASCII编码,但ASCII编码只能够用来表示拉丁字母、数字以及一些特殊符号。
而语言不止英语一种,例如中文一个字节是不够表示的,最少需要两个字节,并且需要兼容ASCII编码,不能与之发生冲突。为了解决传统字符编码方案的局限性,所以Unicode编码应运而生。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
几乎所有电脑系统都支持基本拉丁字母,并各自支持不同的其他编码方式。
Unicode为了和它们相互兼容,其首256字符保留给ISO 8859-1所定义的字符,使既有的西欧语系文字的转换不需特别考量;
并且把大量相同的字符重复编到不同的字符码中去,使得旧有纷杂的编码方式得以和Unicode编码间互相直接转换,而不会丢失任何信息。
Unicode为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF(十六进制),有110多万,每个字符都有一个唯一的Unicode编号,这个编号一般写成16进制,在前面加上U+。
例如:“马”的Unicode是U+9A6C。
Unicode本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
除了直接转换为二进制的策略,还有:UTF-8,UTF-16,UTF-32。
- UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
UTF-8/UTF-16/UTF-32是通过对Unicode码值进行对应规则转换后,编码保持到内存/文件中。 UTF-8/UTF-16/UTF-32都是可变长度的编码方式。
大端与小端
大小端是数据在存储器中的存放顺序。大端模式,是指数据的高字节在前,保存在内存的低地址中,与人类的读写法一致,数据的低字节在后,保存在内存的高地址中。小端与之相反,小端模式,是指数据的高字节在后,保存在内存的高地址中,而数据的低字节在前,保存在内存的低地址中。
比如0x1234, 计算机用两个字节存储,一个是高位字节0x12,一个是低位字节0x34。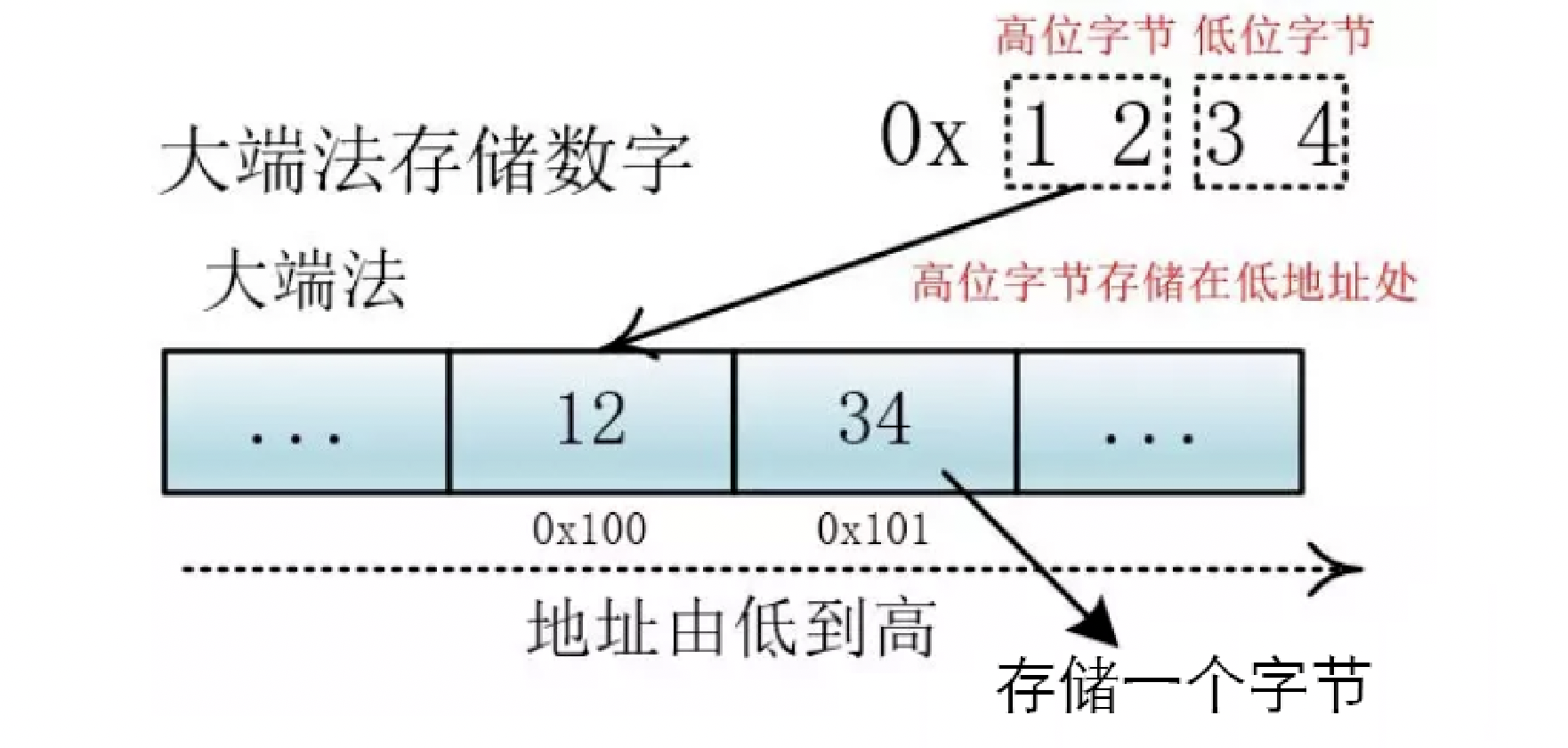
为何会有大端和小端之分呢?
对于 16 位或者 32 位的处理器,因为寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节排放的问题,由于不一样操做系统读取多字节的顺序不同,x86和通常的OS(如windows,FreeBSD,Linux)使用的是小端模式。
但好比Mac OS是大端模式。所以就致使了大端存储模式和小端存储模式的存在,二者并无孰优孰劣。
UTF-8
UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。 它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。
编码规则如下:
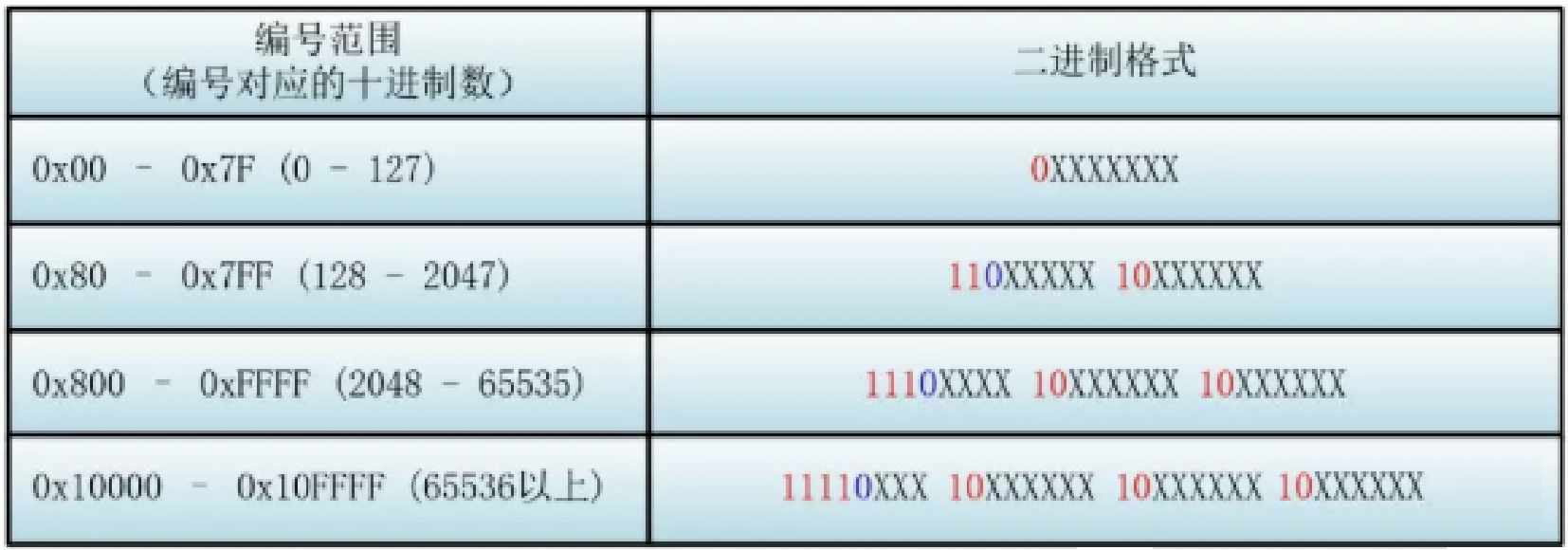
- 对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。
因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。 - 对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
UTF-8编码不存在字节序大小端问题!(因为字节序只影响同时处理多于两个字节的编码方式,比如UTF-16/UTF-32,而UTF-8是按照单字节进行处理的, UTF-8 的编码单元是1个字节)
UTF-8的解码都必须先读取首字节获取字节数,所以必须找到首字节的第一位要么是0,要么是110/1110/11110/111110/1111110,所以上面的“中”字,无论是保存为11100100、10111000、10101101还是10101101、10111000、11100100,都必须要先找到11100100这个字节,所以UTF-8从机制上就能避免字节序的问题。
对于具体的Unicode编号,进行UTF-8编码的方法:
首先找到该Unicode编号所在的编号范围,进而找到对应的二进制格式,然后将该Unicode编号转换为二进制数有(去掉高位的0)最后将该二进制数一次填充入二进制格式的X中,未填充的X变为0。
例如:马的Unicode编号是:0x9A6C,整数编号是39532,其格式为:1110XXXX 10XXXXXX 10XXXXXX,39532对应的二进制为1001 1010 0110 1100,填入为:11101001 10101001 10101100。
UTF-16
注意
UTF-16存在字节序问题。
UUTF-16 使用2字节或者4字节进行编码。
例如,一个“奎”的Unicode码值是0x594E,“乙”的Unicode码值是0x4E59。如果我们的UTF-16字节数据是0x594E,那么这是“奎”还是“乙”?如果大端序,0x594E是“奎”,如果是小端序,0x4E59,是“乙”。
为了弄清楚UTF-16文件的大小尾序,在UTF-16文件的开首,都会放置一个U+FEFF字符作为Byte Order Mark(UTF-16LE以FF FE代表,UTF-16BE以FE FF代表),以显示这个文字档案是以UTF-16编码。
其中U+FEFF字符在UNICODE中代表的意义是ZERO WIDTH NO-BREAK SPACE,顾名思义,它是个没有宽度也没有断字的空白。
字符按照UTF-16进行编码的规则是:
- 字符的值小于0x10000的用等于该值的16位整数来表示。
- 字符的值介于0x10000和0x10FFFF之间的,用一个值介于
0xD800和0xDBFF(在所谓的高8位区)的16位整数和值介于0xDC00和0xDFFF(在所谓的低8位区)的16位整数来表示。 - 字符的值大于0x10FFFF不能按照UTF-16进行编码。
注意:在0xD800和0xDFFF间的值是特别为UTF-16预留,所以不应该将任何字符的值指定为这个区间内的数值。
D800-DB7F High Surrogates 高位替代 895
DB80-DBFF High Private Use Surrogates 高位专用替代 127
DC00-DFFF Low Surrogates 低位替代 1023
高位替代就是指这个范围的码位是两个WORD的UTF-16编码的第一个WORD。
低位替代就是指这个范围的码位是两个WORD的UTF-16编码的第二个WORD。
那么,高位专用替代是什么意思?我们来解答这个问题,顺便看看怎么由UTF-16编码推导Unicode编码。
高位专用替代
如果一个字符的UTF-16编码的第一个WORD在0xDB80到0xDBFF之间,那么它的Unicode编码在什么范围内?
我们知道第二个WORD的取值范围是0xDC00-0xDFFF,所以这个字符的UTF-16编码范围应该是0xDB80 0xDC00到0xDBFF 0xDFFF。
我们将这个范围写成二进制:
1101101110000000 11011100 00000000 - 1101101111111111 1101111111111111
按照编码的相反步骤,取出高低WORD的后10位,并拼在一起,得到:
1110 0000 0000 0000 0000 - 1111 1111 1111 1111 1111
即0xe0000-0xfffff,按照编码的相反步骤再加上0x10000,得到0xf0000-0x10ffff。这就是UTF-16编码的第一个WORD在0xdb80到0xdbff之间的Unicode编码范围,即平面15和平面16。
因为Unicode标准将平面15和平面16都作为专用区,所以0xDB80到0xDBFF之间的保留码位被称作高位专用替代。
UTF-32
注意
UTF-32存在字节序问题。
UTF-32使用4字节进行编码。
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,赢得了效率。
为了保证编码和解码字节顺序问题(因为只有保证编码和解码的规则一致才能保证是同一个字符),所以Unicode规范中推荐的标记字节顺序的方法是BOM(Byte Order Mark)。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。
根据BOM的规则,在一段字节流开始时,如果接收到以下字节,则分别表明了该文本文件的编码。
- UTF-8:
EF BB BF - UTF-16 :
FF FE - UTF-16 big-endian:
FE FF - UTF-32 little-endian:
FF FE 00 00 - UTF-32 big-endian:
00 00 FE FF
而如果不是以上面的那些开头,则程序会以ANSI,也就是系统默认编码读取。 如同样是字符“A”,在以下几种格式中的存储形式分别是﹕
- UTF-16 big-endian :
00 41 - UTF-16 little-endian :
41 00 - UTF-32 big-endian :
00 00 00 41 - UTF-32 little-endian :
41 00 00 00